Key Insight: Train on Kenya data, deploy to Somalia
Classification approach: "Kenya soil type A → Use DAP" cannot generalize to Somalia (no "Somalia" class).
Regression approach: f(N, P, K, rainfall, pH, temp) → yield can transfer better because it models
agronomic relationships rather than geographic labels. That still requires local validation before
the signal is used for high-cost decisions.
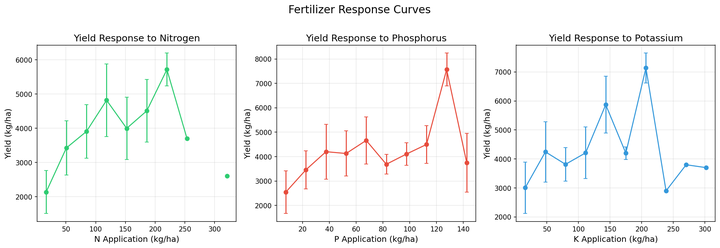
Universal plant biology
Mitscherlich's law of diminishing returns applies everywhere.
Nitrogen uptake, phosphorus availability, and potassium dynamics
follow the same biochemical pathways regardless of location.
Universal soil chemistry
pH effects on nutrient availability are the same in Somalia as Kenya.
Sandy soils leach nutrients the same way globally. Cation exchange
capacity follows the same physical laws everywhere.
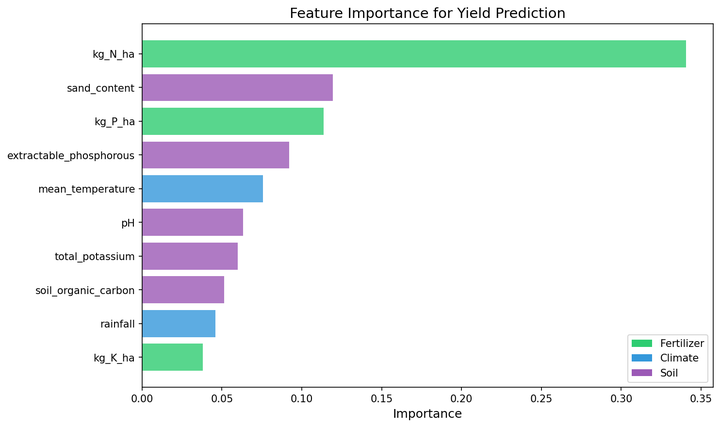
Universally measurable features
Soil tests work the same everywhere. Weather data is globally available
via APIs and satellites. No country-specific features needed, just
soil, climate, and management inputs.
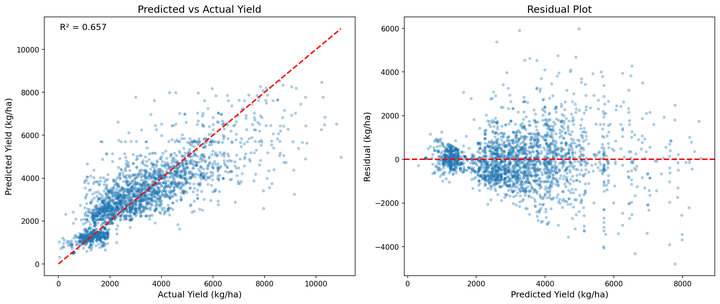
Cross-environment validation: Simulating "new country" predictions
We validated generalization by grouping data by climate/soil environment and testing the model
on held-out environments. Even when predicting for "unseen regions," the model maintains
predictive power, demonstrating that universal agronomic relationships transfer.
Fold 1 (Dry/Sandy): R² = 0.27, RMSE = 1,939 kg/ha
Fold 2 (Moderate): R² = 0.25, RMSE = 1,590 kg/ha
Fold 3 (Humid/Clay): R² = 0.27, RMSE = 1,888 kg/ha
Fold 4 (High Rainfall): R² = 0.39, RMSE = 1,504 kg/ha
Fold 5 (Mixed): R² = 0.39, RMSE = 1,318 kg/ha
Mean R² across environments: 0.31 ± 0.06